问鼎app官方下载 第七届工程训练比赛之智能垃圾分类
2021年第七届工程训练综合能力大赛简介:垃圾智能分类
前言:这是我第一次写博客,想把这半年多备赛的心得记录下来,分享给大家,如果有错误,欢迎大家指出。
如果需要代码请加QQ:1287073476(备注用途)(如有小额补偿请谅解)
比赛成绩:1分23秒(播放宣传片至满载结束)
基本配置:
1.硬件:STM32双直流电机驱动器、雅博K210开发板、maixK210淘宝链接、OV5640摄像头、显示屏、996(995)舵机稳压模块
2.软件:yolov3 maixpyIDE kflash-gui(下载固件)
3 人员:由三名大二学生组成的团队(两名机械师和一名电子控制)
赛事简介
省赛4月26日开始,26日晚上开始提交作品,27日上午9点半到11点半,我们训练了十种垃圾:小矿泉水瓶、易拉罐、1号电池、2号电池、5号电池(都是南孚的)、棉签、烟头、碎瓷片、小西红柿、切好的胡萝卜(片)。比赛现场,两个小组一起入场,我们组成绩1分23秒(从播放宣传视频到满载结束),时间排名第一,文件17分综合排名第二。看了很多学校的垃圾分类设备,开发板最顶级的配置是NVIDIA,大部分是树莓派或者openmv,有的还算准时。我们的垃圾桶包装也很到位,没有裸露的电线,还贴了墙纸,视觉效果还可以。
心灵之旅
接到这个项目的时候,我刚结束校园赛,已经熟练掌握了STM32f103,看了比赛题目后上网查资料,机器视觉、图像分类这几个字第一次浮现在我的脑海里,因为之前没有接触过,所以更是一头雾水。不过还好有一位电控学长带队,初步方案是openmv+stm32。于是开始研究openmv,由此开启了学习python的旅程。在花了大概两周时间搞定垃圾识别后,发现openmv很火(热手宝1号),引脚很少,达不到比赛要求。在四川省赛结束后,我重新确定了方案:(热手宝2号)+stm32。在确定树莓派的那段时间,看到一篇博客,对我帮助很大,感谢这位博主让我学会了使用opencv-python识别自定义物体。 学完之后练习了一下垃圾识别,发现完全达不到比赛的要求,识别率很低,基本识别不出来。于是接下来就老老实实去研究tensorflow了,顺便进入了在树莓派上安装各种依赖的时期。树莓派用不了多久,学校就放假了,就拿回家研究了几天,想过在树莓派上安装pycharm来跑代码识别垃圾,但是最后的结果很卡。也在网上查了一篇用树莓派实现垃圾分类1的博客,也很有帮助。但是因为时间紧迫等原因,没能按照博主的指示去做,就换了K210。雅博K210的资料很全,但是用的是C语言,网上大部分图像识别的开源编程语言都是python,有一次无意中在Bilibili上看到了一个视频。 K210用的就是maixpy,于是就想着把他那一套装到我的Yabo开发板上。谢天谢地,我成功了!后来才知道,两款K210芯片是一样的,所以能用。而且maix开发板是基于openmv的,所有的资料教程和maixIpyDE也是基于openmv IDE的。所以有了之前的openmv基础,我很快就上手了,每天都有大的突破。自定义垃圾大概一个星期就能识别出来,识别率大概在80%左右。之后的事情就简单了:训练模型,提高识别率。
K210使用参数
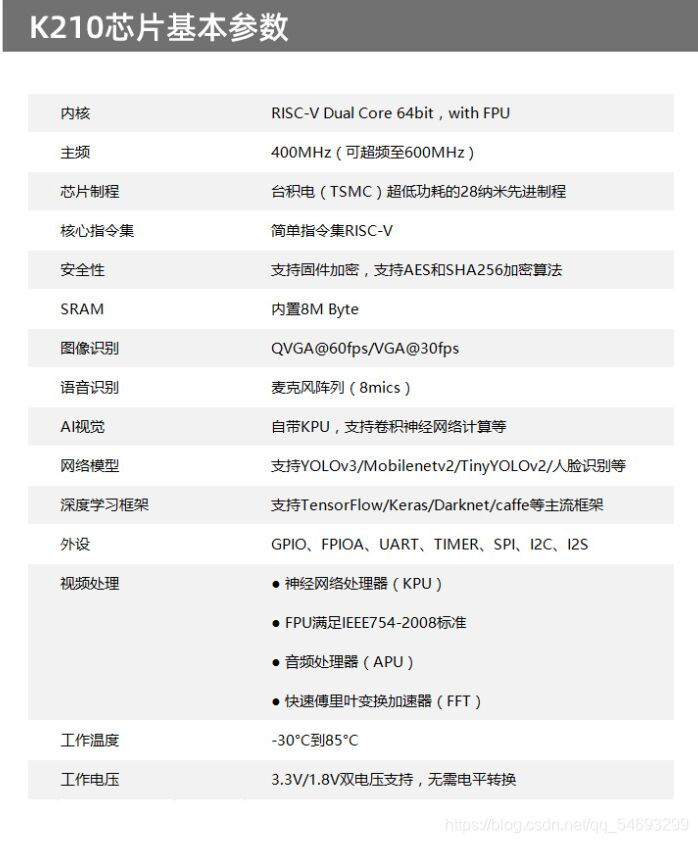


K210maixpy入门教程 K210相机
K210板载摄像头是ov2640,200万像素,识别视野较小。用来识别还可以,但是对于比赛来说,为了识别小垃圾,就得换成像素更高的摄像头了。这里的坑:千万不要找广角摄像头,个人觉得24P针脚的广角摄像头,畸变比较大,不推荐。这里推荐使用ov5640摄像头,像素高500万像素,识别视野比ov2640大。如图
ov2640

ov5640

有关 K210 数据收集的详细信息,请参见此处
数据采集方式:1.手机拍照格式为1:1,224*224
2.用开发板拍照:使用开发板采集数据,使用此脚本采集图像(阅读图像采集用法进行采集图像)
数据集集合文件格式如下:
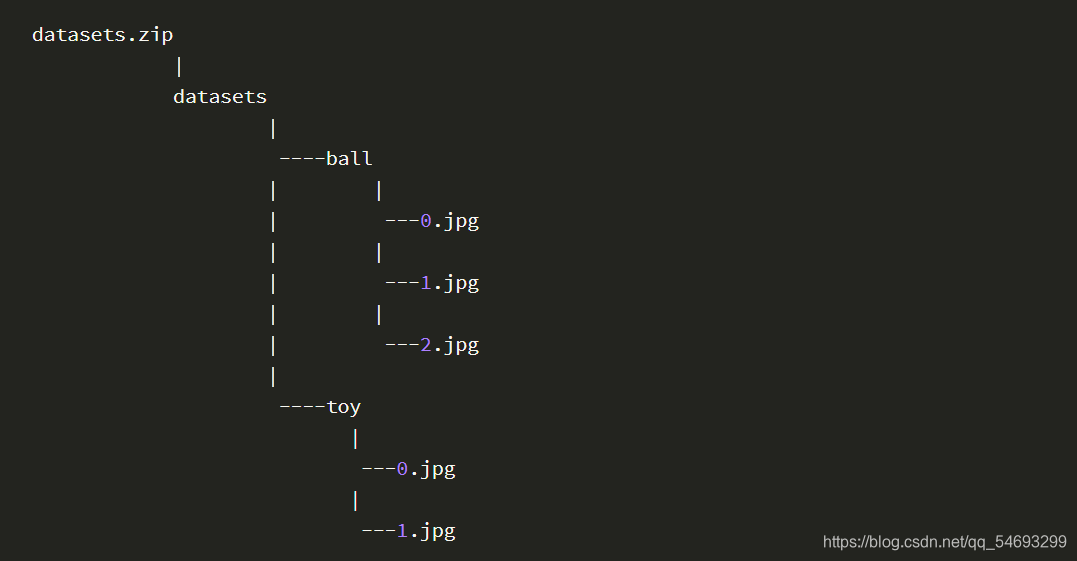
K210本地培训
maixpy的基础文档很详细问鼎app官方下载,大家都能看懂,我主要讲一下我遇到的坑:
首先你需要一台Linux系统的电脑,如果你的主系统是Windows,那么可以使用以下系统环境:
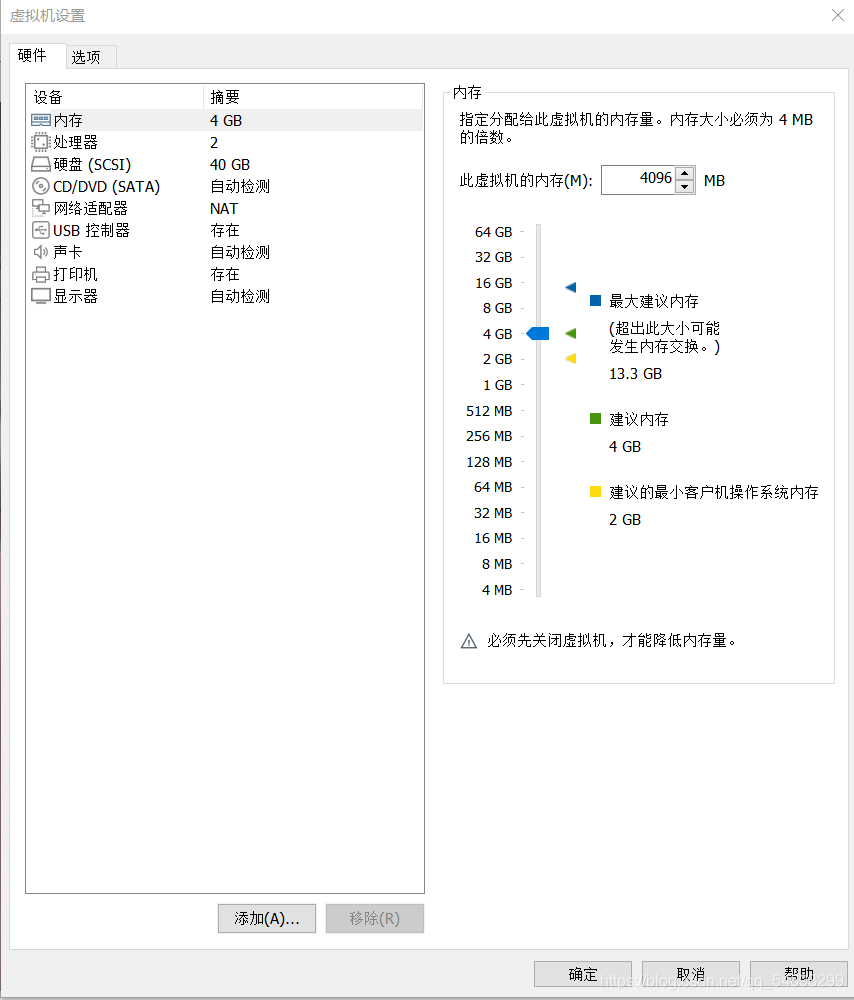
我踩过的坑:安装双系统训练模型。因为找了个安装Ubuntu20.4双系统的教程,没有按照博主的指示,私自安装了,导致Ubuntu覆盖,Window系统全军覆没/(ㄒoㄒ)/~~重新安装Window系统花了不少时间,在此感谢队友贡献电脑(我在他们的电脑上安装了Ubuntu,哈哈哈哈,鞠躬!)所以安装双系统一定要小心!建议先在vmware虚拟机上安装本地训练:VMware虚拟机安装教程,vmware安装Ubuntu20.04教程,建议给Ubuntu配40G内存!亲测大内存训练快!(40G就够了)记得做个共享文件夹,方便。初次接触,建议先用CPU进行训练,环境安装会简单很多。 文档教程中关于CPU训练的方法已经很详细这里就不再赘述了,下面的使用方法摘录自仓库的README,如有出入以仓库的README为准,注意区分。
CPU 本地训练教程
以下是部分本地训练代码
import os
curr_dir = os.path.abspath(os.path.dirname(__file__))
# kmodel convert
# "/ncc/ncc" # download from https://github.com/kendryte/nncase/releases/tag/v0.1.0-rc5
ncc_kmodel_v3 = os.path.join(curr_dir, "..", "tools", "ncc", "ncc_v0.1/ncc")
sample_image_num = 20 # convert kmodel sample image (for quantizing)
# train
allow_cpu = True # True
# classifier
classifier_train_gpu_mem_require = 2*1024*1024*1024
classifier_train_epochs = 70
classifier_train_batch_size = 5
classifier_train_max_classes_num = 15
classifier_train_one_class_min_img_num = 40 # 一个类别中至少需要的样本数量
classifier_train_one_class_max_img_num = 2000 # 一个类别中最多需要的样本数量
classifier_result_file_name_prefix = "maixhub_classifier_result"
# detector
detector_train_gpu_mem_require = 2*1024*1024*1024
detector_train_epochs = 40
detector_train_batch_size = 5
detector_train_learn_rate = 1e-4
detector_train_max_classes_num = 15 # 最多能训练多少类
detector_train_one_class_min_img_num = 100 # 一个类别中至少需要的样本数量
detector_train_one_class_max_img_num = 2000 # 一个类别中最多需要的样本数量
detector_result_file_name_prefix = "maixhub_detector_result"以下是本地训练的截图:
本地训练的好处:classifier_train_epochs = 70(可修改迭代次数,网站上模型训练默认迭代次数是40) 没有数据集训练包20MB的限制!这个太牛了,我最初还担心如果比赛中有十几种垃圾,数据集压缩包会太大没法训练,这个好像没有必要。最主要的好处就是不用排队问鼎app官网下载安装,在网站上训练是需要排队等服务器的,每次只能训练一个用户,少则半小时四十分钟,多则一两个小时,如果排队的人太多甚至可能需要一天的时间。 本地训练随时可以进行,我的数据集大概2000个,训练时间基本在40分钟左右(vmware虚拟机训练)。这也是我做本地训练的初衷。
K210训练注意事项 虽然本地训练数据集没有像网站上一样要求小于20MB,但是数据集越多,训练时间就越长。而且训练时间越长,效果也不一定越好。一般迭代次数在60次左右,当loss降到0.1左右,accuracy在0.9左右的时候,模型效果还是不错的。本地训练还要求每个数据集的格式是224*224。在定制物体识别的本地训练时,要求每个物体的数据集明显不同,背景丰富,每个物体的数据集数量建议在200+。同一个数据集每次训练的模型效果是不一样的。拍照采集数据集时,建议保证环境明亮。 K210垃圾分类代码:
轻微地
总结
准备期间,遇到了很多困难,第一次做图像分类和深度学习,也没有前辈的经验。一步步,从stm32问鼎娱乐官网下载,到openmv,到树莓派,最后确定了K210,一步步就像拓荒,不断发现、踩坑。但还好有队友陪伴,有队长带领,有家人的鼓励,一步步克服困难,最终成功登顶!期间,我不停地训练模型,无数次熬夜,遇到瓶颈,最困难的时候没有放弃,选择迎难而上,哪怕和队友吵了一架,也不影响我们为了比赛的最终目标,怀着一切为了比赛的信念,勇敢前行。有些事,不坚持才会看到希望,但坚持才能看到希望! 也在此向一直陪我熬夜的兄弟们致敬!最后兄弟们,全国赛清华见!
 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论