问鼎app官方下载 深度学习训练tricks总结(均有实验支撑)

作者:Jones@Zhihu
来源
编辑丨集市平台
极端市场指南
本文作者模拟并复现了深度学习训练过程中可能遇到的各种情况,并尝试解决这些问题。文章重点讨论了学习率、动量、学习率调整策略、L2正则化和优化器。>>
深度模型是个黑盒子,而且我们这次也没有尝试超深超宽网络,所以结论只能提供先验,而不是标准答案!同时不同的任务也可能得出不同的结果,比如分割,所以要具体问题具体分析!
摘要;关键词;动机
前段时间参加了几个CV比赛,发现如下问题:虽然理论知识理解的很好,也跑过实验、论文代码,但是实际实现的时候总是会出现一些奇怪的问题,有点难以解决,于是打算尽量模拟复现一下情况,尝试解决并解释(但解释只能是自洽的,毕竟是黑箱实验),以免以后遇到类似情况没有解决,只能另想办法。
这个黄金周,我乖乖的在研究所做了几天实验,主要围绕以下几个关键词:
学习率;动量;学习率调整策略;L2正则化;优化器
(所有结论都有实验支持,但我丢失了部分实验数据....555)
思维
根据这些实验以及一些资料(主要是Andrew Ng的《机器学习向往》),总结出以下几个基本原则:
影响模型性能的因素:
2.影响模型过拟合的因素:
稍微解释一下:模型的表达能力对于模型是否过拟合确实有一定的影响,但是选择合适的正则化强度可以有效缓解这种影响!所以我并没有把模型的表达能力作为过拟合的影响因素。而且Andrew Ng的书(机器学习向往)也表达了类似的想法(很开心自己和大佬有同样的想法)。
实验环境
Resnet-18
Cifar-10
细节
学习率和动量
我会把学习率和动量放在一起说,因为我发现这两个东西是天生一对。熟悉深度学习的朋友应该知道,学习率过大或者过小都会存在问题:
学习率过大,会导致模型无法进入局部最优,甚至导致模型爆炸(无法收敛)
学习率太小会导致模型训练缓慢问鼎娱乐下载入口,浪费时间
有没有办法让模型快速训练并收敛?有的!
经过四次实验,我得出以下结论:
使用较大的学习率+较大的动量可以加快模型训练并快速收敛
实验设计如下(忘记保存实验图了,抱歉!):
实验一:
小学习率+小动量
结果:模型训练速度慢,虽然收敛,但是收敛速度很慢,在验证集上的表现很稳定
实验2:
小学习率+大动量
结果:模型训练速度慢,虽然收敛,但是收敛速度很慢,在验证集上的表现很稳定
实验3:
大学习率+小动量
结果:模型训练速度快,但收敛困难,验证集上的表现波动很大,表明模型很不稳定
实验4:
大学习率+大动量
结果:模型训练快速,收敛迅速,在验证集上表现非常稳定。
我觉得这个原因可以从两个角度来解释问鼎app官网下载安装,一个是向量加法的特殊性,另一个是从集成模型的角度来解释。第一个角度这里就不说了,因为我不想画图,我先从第二个角度说一下:
大的学习率意味着不稳定,但是因为这个学习率也能让模型往正确的优化方向走,所以你可以理解为,大的学习率就是弱机器学习模型;当你用了很大的动量时,意味着这一次的学习率对最终的模型优化起到的作用更小,也就是使用大动量->单个损失函数的比例低,相当于我的模型的优化就是由这个+过去很多个学习率计算出来的综合结果(弱机器学习模型)构成的综合模型,对吧?所以,效果比较好。
顺便提一下,当模型很不稳定的时候,如果某一刻出现了很好的结果,比如98%的准确率,并不代表这一刻这个模型就是一个好的模型,因为这时候你的模型很可能是过拟合了验证集!不信你可以试着单独分一个测试集(我参加脑PET识别比赛的时候摔倒过)。
2.学习率调整策略
之前我几乎没用过学习率调整策略,因为觉得很可笑而且效果不大,不过前段时间跟一个小伙打华录杯的时候看到他用余弦退火效果不错,就决定试一试,结论是:真香!
抱歉,我这里也忘记保存实验图片了,抱歉!
我尝试了3种学习率调整策略:1. ReduceLROnPlateau;2.余弦退火;3. StepLR
综上所述:
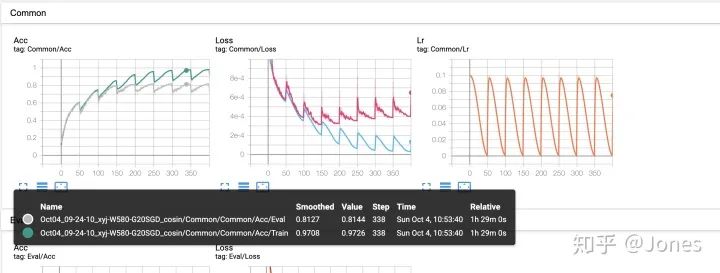
图 1
3. L2 正则化
正则化主要有两种,一种是L1,一种是L2。由于pytorch自带了L2,所以我就用了L2(呵呵)。直接上结论吧:
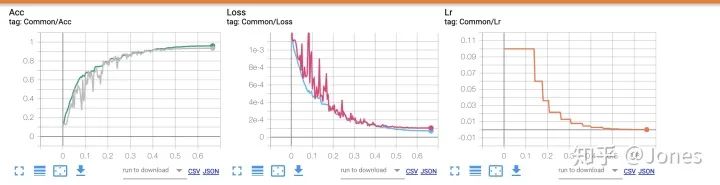
图 2
4. 优化器
我保存了优化器部分的图片!
其实这里我们不仅测试了优化器,还测试了优化器+学习率策略+动量
其实我想要做的是找到一个最优解作为我的先验知识(害处,用人的话来说:我想知道哪种组合更好,然后先尝试这种组合)
我做了几个实验:
结论(图3):
图 3
第 2 组:
首先解释一下ReduceLROnPlateau的两种模式:min和max
当模型为min时,如果指标A在一段时间内没有下降,则学习率衰减。
当模型处于最大值时,如果指标A在一段时间内没有增加,则学习率衰减。
当我选择 ReduceLROnPlateau 的模式为 min 时问鼎app官网下载安装,指标为 acc。有趣的是,它的收敛速度非常快(比 max 的模式还快)。我猜原因应该是:
当acc增大时,说明优化方向正确,优化速度应该放慢!但是本次实验中,最优解比max模式的模式要差(min模式最优解为0.916,max为0.935),原因有两点:
1、是因为lr的衰减速度太快,从而导致学习率太低,无法进行训练;(我后来做了实验,证明是这个原因!)
2.因为一遇到可优化区域就降低学习率,所以很有可能导致模型过早进入局部最优(不过后来觉得这个理由站不住脚,哈哈哈,因为就算用其他优化器,也会有陷入局部最优的问题,所以这一点并不重要,但为了保留从实验到笔记的思考过程,我还是没有删除这一点。)
对于原因1,我后来做了实验来验证,实验的思路是通过减小学习率衰减周期和衰减系数的值/设置最小学习率来保证后面的学习率不会太小,最终解决了最优解的问题。
图 4
结论(图4):
第 3 组:
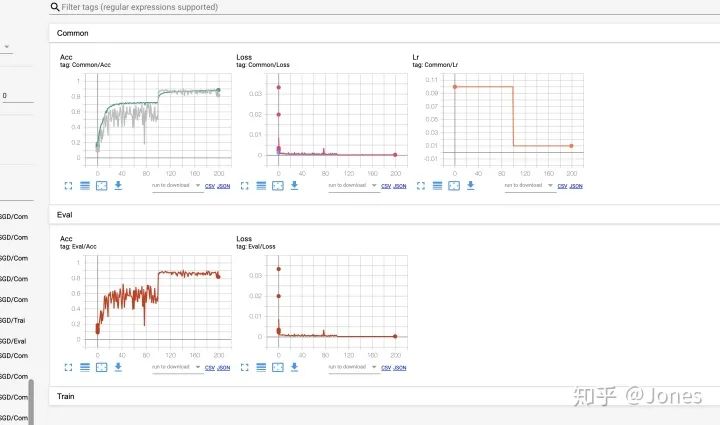
图 5
图 6
综上所述:
对了:我也试过模拟退火+Adam,但是因为退火幅度太大,效果更差(我的错)。下次试试正常幅度退火。
经验:
从上面的实验可以看出,纪念碑很重要,它让本来有点垃圾的SGD一飞冲天(怪不得论文都喜欢用这对)。这时候加入一些学习率调整策略(annealing/ReduceLROnPlateau)能使Adam确实比SGD好很多,但是比最优组合(SGD+momentum+学习率调整策略)要弱一点点。(在Char Siu师兄的群里,有高通高手告诉我可以试试用nadam,因为nadam可以理解为Adam+纪念碑,但是因为pytorch没有对应的API,所以懒得去试,不过相信应该会很猛!)
 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论