问鼎娱乐官网下载 全方位、无死角的开源,邢波团队LLM360让大模型实现真正的透明
我们需要更深入地分享。
开源模型显示出其剧烈的活力,不仅增加了数量,而且表现越来越出色。图灵奖得主Yann Lecun也叹了口气:
专有模型在技术绩效和创新能力方面具有非凡的力量,但是它们的非开放源性质已成为LLM发展的障碍。尽管一些开源模型为从业人员和研究人员提供了多种选择,但大多数人仅透露最终模型的权重或推理代码,而技术报告的增加将其范围限制为顶级设计和表面统计。这种封闭的源策略不仅限制了开源模型的发展,而且还极大地阻碍了整个LLM研究领域的发展。
这意味着需要更全面,更深入地共享这些模型,包括培训数据,算法详细信息,实施挑战和绩效评估详细信息。
来自脑,Petuum和Mbzuai的研究人员共同提出了LLM360。这是完全开源的LLM的倡议,提倡社区与LLM培训有关的一切,包括培训代码和数据,模型检查点和中间结果。 LLM360的目标是使LLM培训过程透明并且可以为每个人重现,从而促进开放和协作的人工智能研究的发展。

研究人员开发了LLM360的体系结构,重点介绍其设计原则和完全开源的原因。他们详细介绍了LLM360框架的组件,包括数据集,代码和配置,模型检查点和指标。 LLM360设置了当前和将来的开源模型的透明度样本。
研究人员在LLM360的开源框架:Amber和Crystalcoder的开源框架下发布了两种大型语言模型。 Amber是一种基于1.3T令牌的7B英语模型。 CrystalCoder是基于1.4T代币预先训练的7B英语和代码语言模型。在本文中,研究人员总结了这两个模型开发的细节,初步评估结果,观察结果以及从中汲取的经验和经验和经验。值得注意的是,在释放时,Amber和Crystalcoder在训练过程中分别保存了360和143个模型检查点。

接下来,让我们看一下文章的具体内容。
LLM360的框架
LLM360将为LLM预培训期间收集的数据和代码提供标准,以确保可以在社区中更好地分发和共享现有工作。它主要包含以下部分:
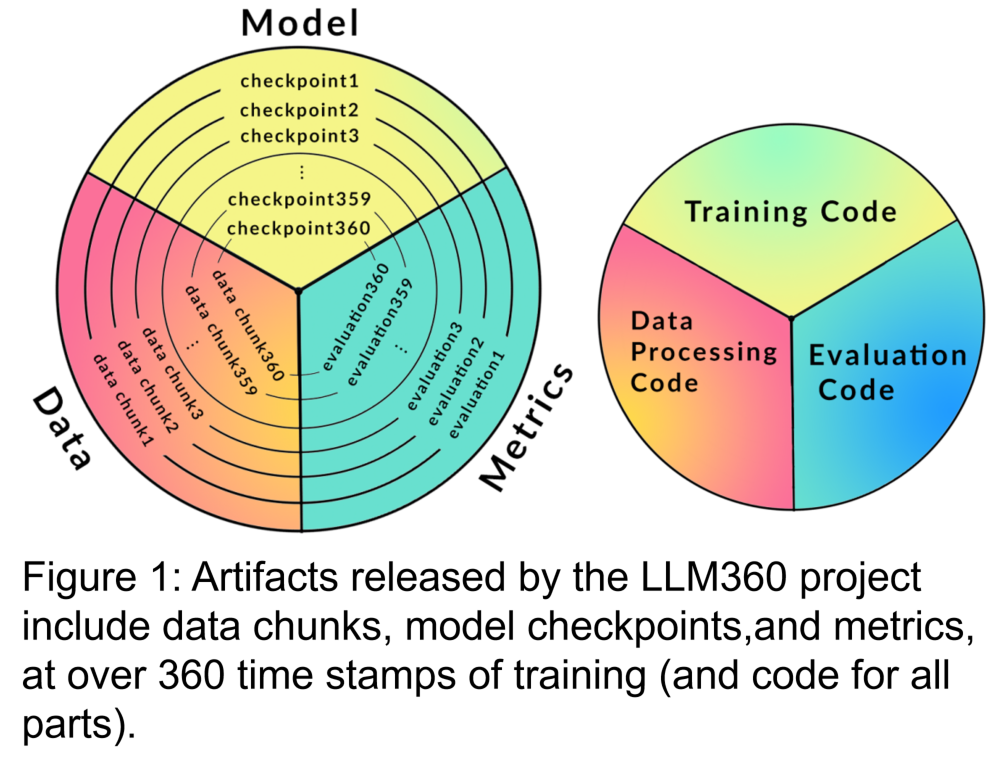
1。培训数据集和数据处理代码
预训练的数据集对于大语模型的性能至关重要。因此,重要的是要了解预先训练的数据集,以评估潜在的行为问题和偏见。此外,披露的预训练数据集有助于在随后进行微调和适应各个领域时提高LLM的可扩展性。最近的研究表明,对重复数据的培训不成比例地降低了模型的最终表现。因此,暴露原始预处理数据有助于避免在下游进行微调或继续在特定域中预处理时使用重复数据。基于上述原因,LLM360主张披露大语模型的原始数据集。在适当的情况下,还应披露有关数据过滤,处理和培训顺序的详细信息。
2。培训代码,超参数和配置
培训代码,超参数和配置对LLM培训的性能和质量有重大影响,但并非总是公开披露。在LLM360中,研究人员的开源所有培训代码,培训参数以及训练框架的系统配置。
3。模型检查点
定期保存模型检查点也很有用。它们不仅对于训练期间的失败恢复至关重要,而且对培训后的研究也很有用。这些检查点使后来的研究人员可以在不从头开始培训的情况下继续从多个起点进行培训模型,这有助于重复且深入研究。
4。性能指标
培训LLM通常需要数周到几个月,而培训期间的进化趋势可以提供有价值的信息。但是,目前,只有证人可以使用详细的日志和中间培训指标,这阻碍了对LLM的全面研究。这些统计数据通常包含难以检测的关键见解。即使是简单的分析,例如这些措施的方差计算也会发现重要发现。例如,GLM的研究团队提出了一种梯度收缩算法,该算法通过分析梯度规范行为来有效地处理损失尖峰和NAN损失。
琥珀色
Amber是LLM360“ Big Family”的第一位成员,还发布了其微调版本:Amberchat和Ambersafe。

数据和模型详细信息
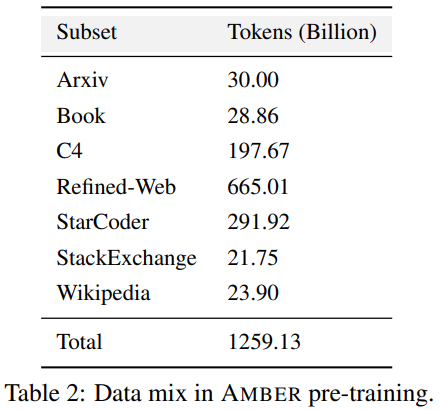
表2列出了包含1.26 T令牌的琥珀预训练数据集的详细信息,包括数据的预处理,格式化,数据混合比以及琥珀的体系结构详细信息和特定的预训练的超级参数。有关详细信息,请参阅项目主页上的LLM360代码基础。
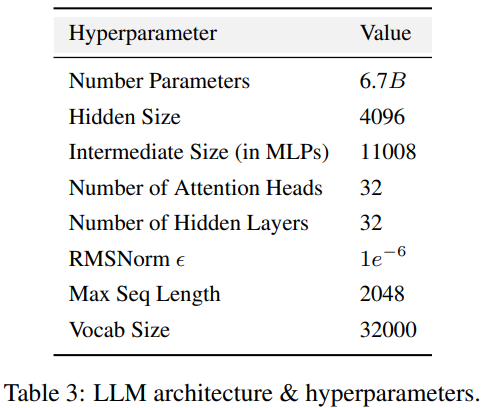
Amber采用了与Llama 7B4一致的模型体系结构,表3总结了LLM的详细体系结构配置。
在训练过程和超参数方面,研究人员尽可能地遵循遍历美洲驼的预训练超参数。使用ADAMW优化器对Amber进行训练,并具有高参数:β₁= 0.9,β₂= 0.95。同时,研究人员还发布了几种微调版本的琥珀色:Amberchat和Ambersafe。根据Wizardlm指令培训数据集进行了微调。有关更多参数详细信息,请阅读原始文本。
实验和结果
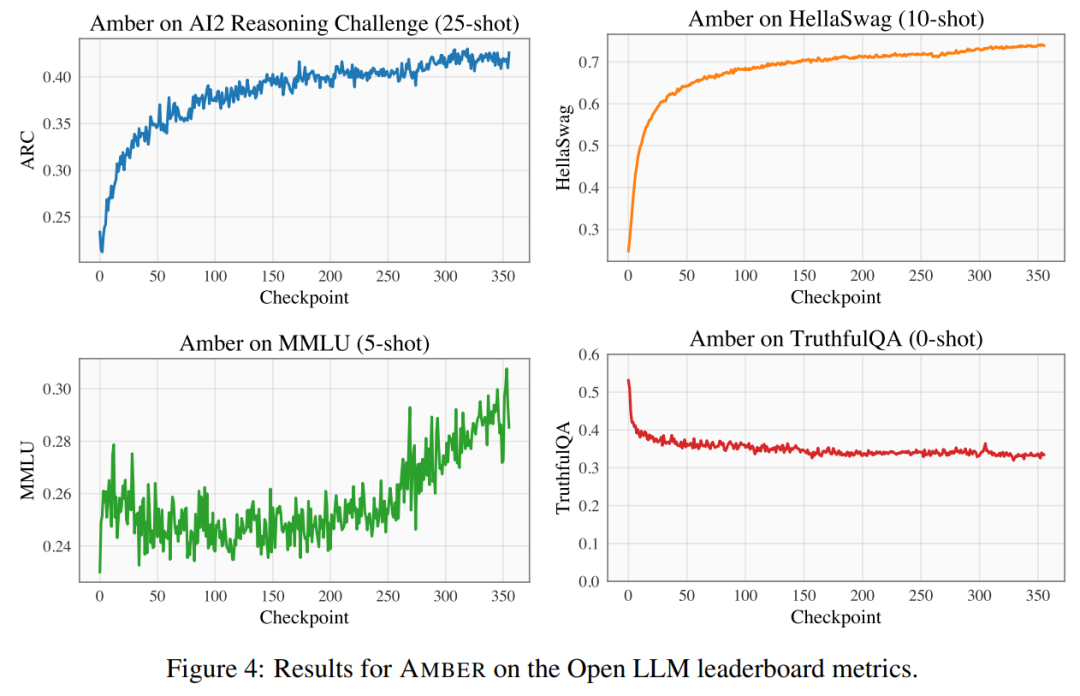
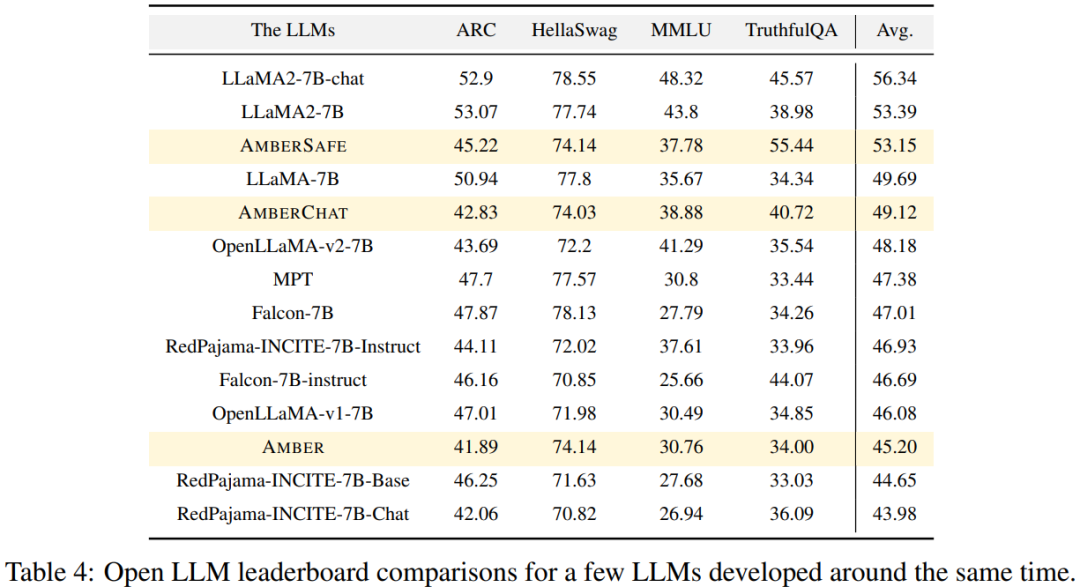
研究人员在开放LLM排名上使用了四个基准数据集来评估琥珀的性能。如图4所示,在Hellaswag和Arc中,琥珀的得分在预训练期间单调增加,而随着训练的进行,真实性的得分降低。在MMLU数据集中,琥珀的得分在预训练的初始阶段下降,然后开始上升。
在表4中,研究人员将琥珀色的模型性能与在类似时间段内训练的模型(例如Openllama问鼎娱乐电子游戏,Redpajama-incite,Falcon,MPT等)进行了比较。许多模型都受到了Llama的启发。可以发现,琥珀在MMLU中得分较高,但在ARC中的表现稍差。与其他类似模型相比,琥珀的表现相对强。
水晶雕像
LLM360“大家庭”的第二个成员是CrystalCoder。

CrystalCoder是基于1.4 T令牌培训的7B语言模型,在编码和语言能力之间取得了平衡。与大多数以前的代码LLM不同,CrystalCoder是通过仔细混合文本和代码数据来最大化这两个领域的实用性来训练的。与Code Llama 2相比,CrystalCoder的代码数据是在预训练过程中引入的。此外,研究人员还培训了Python和Web编程语言的CrystalCoder问鼎app官方下载,以提高其作为编程助理的实用性。
模型架构
CrystalCoder采用与Llama 7B非常相似的架构,并添加了最大更新参数化(MUP)。除了这种特定的参数化外,研究人员还进行了一些修改。此外,研究人员还使用了分层,而不是RMSNORM,因为CG-1架构支持了分层的有效计算。
实验和结果
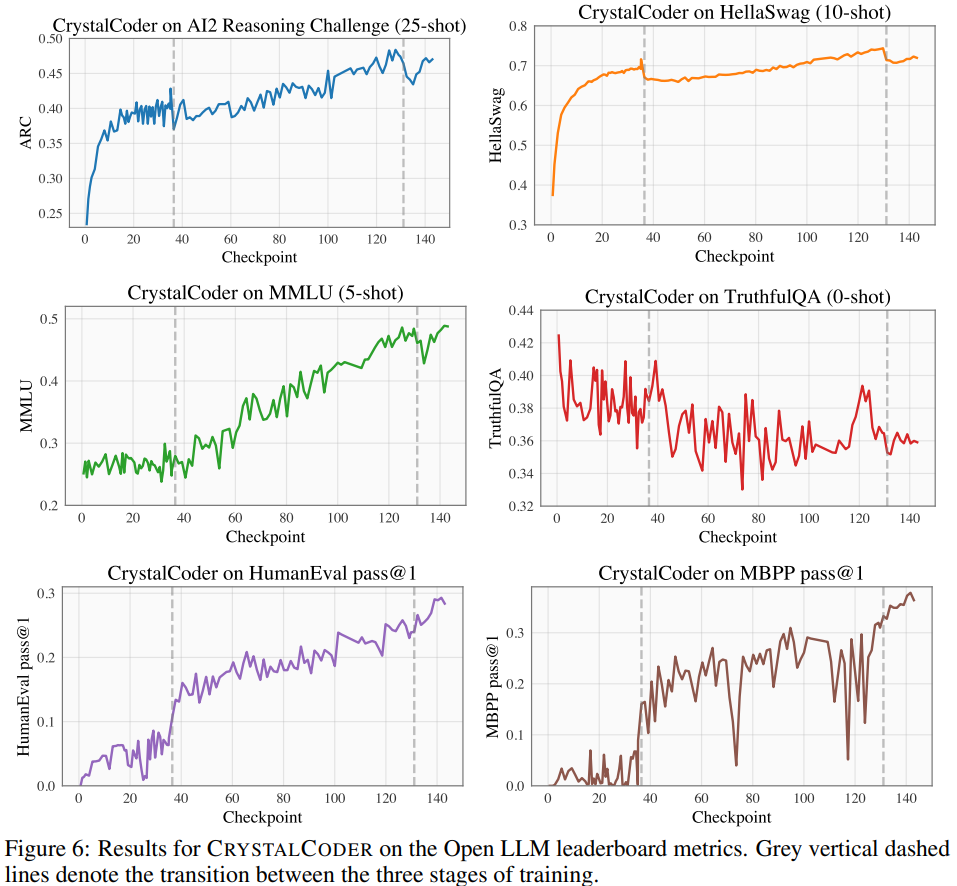
如图6所示,研究人员在Open LLM排行榜和编码的基准数据集中在四个基准数据集上对模型进行了基准测试。
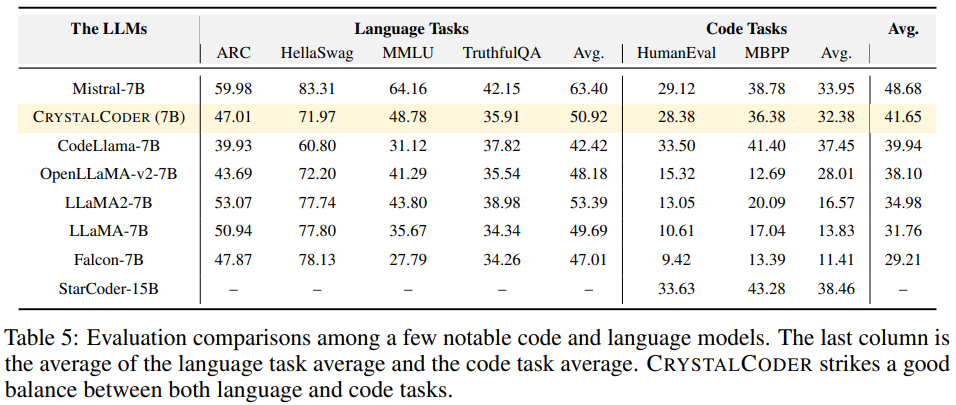
从表5可以看出,CrystalCoder在语言任务和代码任务之间取得了良好的平衡。
分析360
Pythia等人的先前工作。表明可以通过分析模型的中间检查点进行深入研究。研究人员希望LLM360还可以为社区提供有用的参考和研究资源。为此,他们发布了Analysis 360 Project的初始版本,这是一个有组织的存储库,用于对模型行为的多方面分析,包括模型特征和下游评估结果。
作为分析一系列模型检查点的一个例子,研究人员对LLM中的记忆进行了初步研究。最近的研究表明,LLM可能会记住大多数培训数据,并且可以在适当的提示中提取这些数据。此内存不仅存在泄漏私人培训数据的问题,而且如果培训数据包含重复或专业,也可以降低LLM的性能。研究人员发布了所有检查点和数据,因此他们可以在整个训练阶段对记忆进行全面分析。
以下是本文中使用的内存评分方法,该方法指示了长度为k的提示下L的后续长度的令牌的准确性。有关特定的内存得分设置,请参阅原始文本。
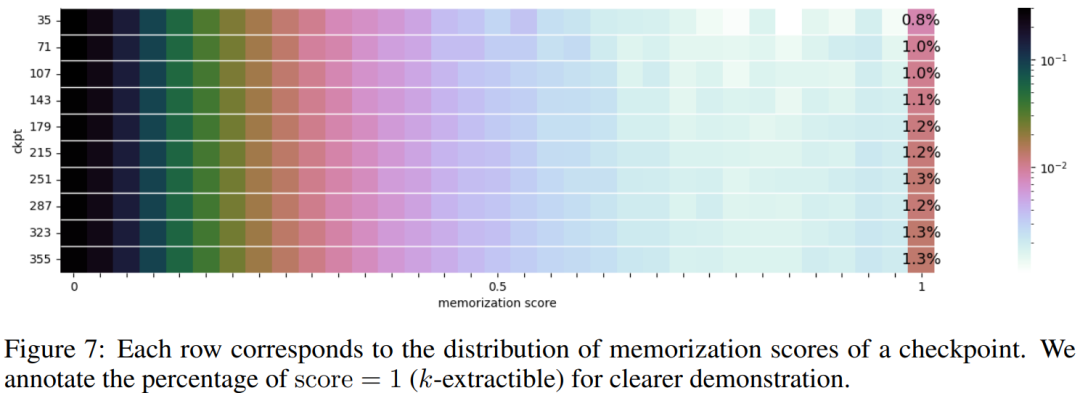
图7显示了10个选定检查点的内存得分分布。
研究人员根据选定的检查点对数据块进行了分组,并为图8中每个检查点的每个数据块组绘制了每个数据块组的内存得分。他们发现,琥珀检查点比以前的数据更多地记住了最新数据。此外问鼎娱乐下载入口,对于每个数据块,额外训练后的内存评分将略有下降,但此后将继续上升。
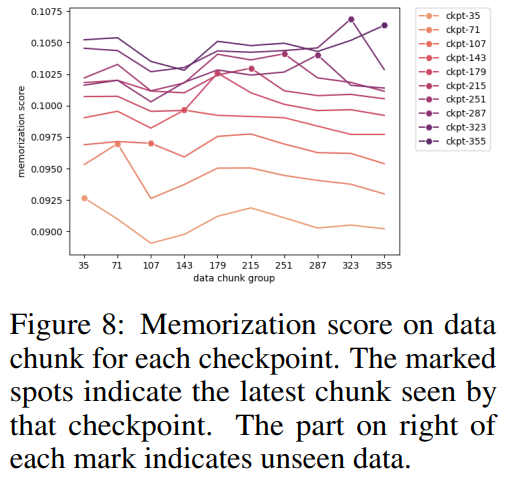
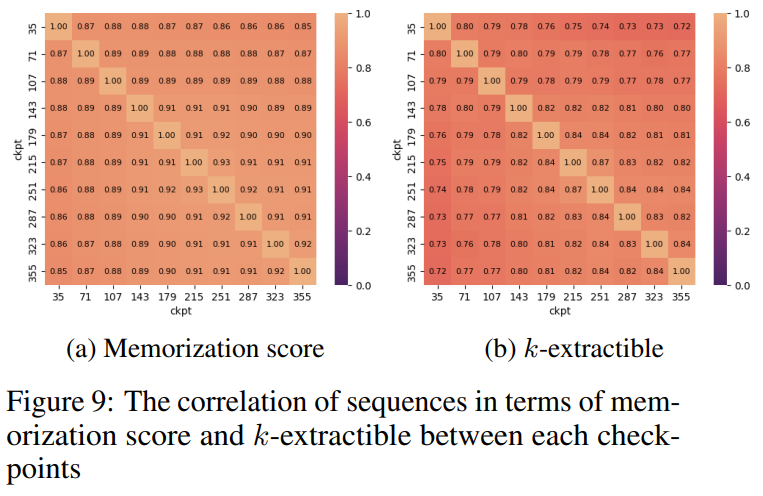
图9显示了内存得分和可提取K值的序列之间的相关性。可以看出,检查点之间存在很强的相关性。
总结
研究人员总结了关于琥珀色和水晶编码器的观察结果和一些启示。他们说,培训是许多学术实验室或小型机构负担不起的一项计算密集的任务。他们希望LLM360能为用户提供全面的知识,了解LLM预培训期间发生的事情而无需自己做。
 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论